

Na pytanie “czy JavaScript jest jednowątkowy?”, większość z nas bez wahania odpowie twierdząco. Okazuje się jednak, że za pomocą nowoczesnych przeglądarek internetowych i wykorzystania dostarczanego przez nie API, możemy wprowadzić namiastkę wielowątkowości do świata internetu.
Aplikacje Wielowątkowe
Zanim przejdziemy do głównego tematu artykułu, postanowiłem poświęcić chwilę i wyjaśnić jego tytuł. Wspominam w nim o namiastce wielowątkowości. Dlaczego jednak tylko namiastce? Dlaczego Web Workery nie dają nam pełnej wielowątkowości i czym właściwie różni się ich działanie od aplikacji wykorzystujących wiele wątków? Na te pytania postaram się odpowiedzieć.
Przede wszystkim należy pamiętać, że workery nie są częścią języka JavaScript. Są dostarczane przez przeglądarki internetowe, a to oznacza, że nie można ich wykorzystać w każdym środowisku.
To jednak dopiero pierwsza z różnic. Druga, moim zdaniem równie ważna różnica, to ograniczenia w komunikacji i dzieleniu danych. Przesyłanie danych do wątku workera wymaga serializacji, a ich odczyt po drugiej stronie deserializacji. Niesie to za sobą również ograniczenia związane z rodzajem danych, jakie możemy przesyłać. Oczywiście takie problemy (zazwyczaj) nie występują w językach, które natywnie wspierają wielowątkowość. Mają one znacznie bardziej rozbudowany interfejs do pracy z wieloma wątkami i mogą operować na tych samych obiektach i klasach bez wykorzystywania mechanizmu serializacji. Niestety to również pociąga za sobą pewne problemy (np. Thread Deadlock) i wymaga stosowania kilku dodatkowych mechanizmów w celu synchronizacji stanu pomiędzy wątkami, czy unikania nadpisywania danych przez różne wątki.
Wielowątkowość ma również swoje plusy. Każdy kolejny wątek w takiej aplikacji posiada dostęp do większości API dostępnych w wątku głównym. Niestety nie można powiedzieć tego samego o Web Workerach - są one znacznie bardziej ograniczone w możliwościach i dostępach.
Ostatnia różnica, o której warto wspomnieć, to koszt związany z utworzeniem i utrzymaniem workera. Workery są częścią specyfikacji języka HTML (a nie JavaScript, jak można by pomyśleć), a jedno z pierwszych zdań, które możemy w niej znaleźć, brzmi tak:
Powinniśmy zatem unikać częstego tworzenia nowych i usuwania istniejących już workerów. Sytuacja wygląda nieco inaczej w przypadku innych języków obsługujących wielowątkowość. Tam często tworzymy nowe wątki i kończymy działanie tych, których już nie używamy, a koszt z tym związany jest niezwykle niski i nie obciąża znacząco aplikacji.
Różnic jest więcej, a na dodatek niektóre z nich zależą od języka, do którego porównamy działanie Web Workerów. Nie będziemy analizować ich wszystkich i wchodzić zbyt głęboko w szczegóły dotyczące konkretnego języka programowania. Ten krótki wstęp miał jedynie zaznaczyć, że Worker nie dodaje do JavaScriptu pełnej wielowątkowości, a jedynie jej zalążek. Jeżeli temat wydaje Ci się ciekawy, to warto go zgłębić, ucząc się języka wspierającego wielowątkowość (przykładem może być Java lub C#).
Web Workers
Istnieje kilka typów workerów i każdy z nich ma zupełnie inne zastosowanie. Zanim jednak przejdziemy do omówienia poszczególnych rodzajów, skupmy się na cechach wspólnych.
Worker umożliwia wykonywanie kodu JavaScript w osobnym wątku, a więc nie wpływa negatywnie na responsywność aplikacji lub strony internetowej. Oznacza to również, że kod może być wykonywany równolegle w wątku głównym oraz w wątku workera.
Jeżeli do tej pory nie spotkałeś/aś się z koncepcją wielowątkowości, to czas na krótkie wprowadzenie w temat. Niezależnie od tego, jak długo programujesz w JavaScript, z pewnością wiesz, że jednocześnie może być wykonywana tylko jedna linia kodu, a interpreter wykonuje program od góry do dołu (wyjątkiem są zadania asynchroniczne).
Takie zachowanie może okazać się problematyczne, jeżeli natrafimy na fragment kodu, którego wykonanie zajmuje 500ms (w świecie frontendu jest to wartość niezwykle duża 😉). Przykładem takiej funkcji może być zapytanie do serwera. Wykonujemy zapytanie, a następnie czekamy na odpowiedź. Gdy ją otrzymamy, wyświetlamy ją użytkownikowi.
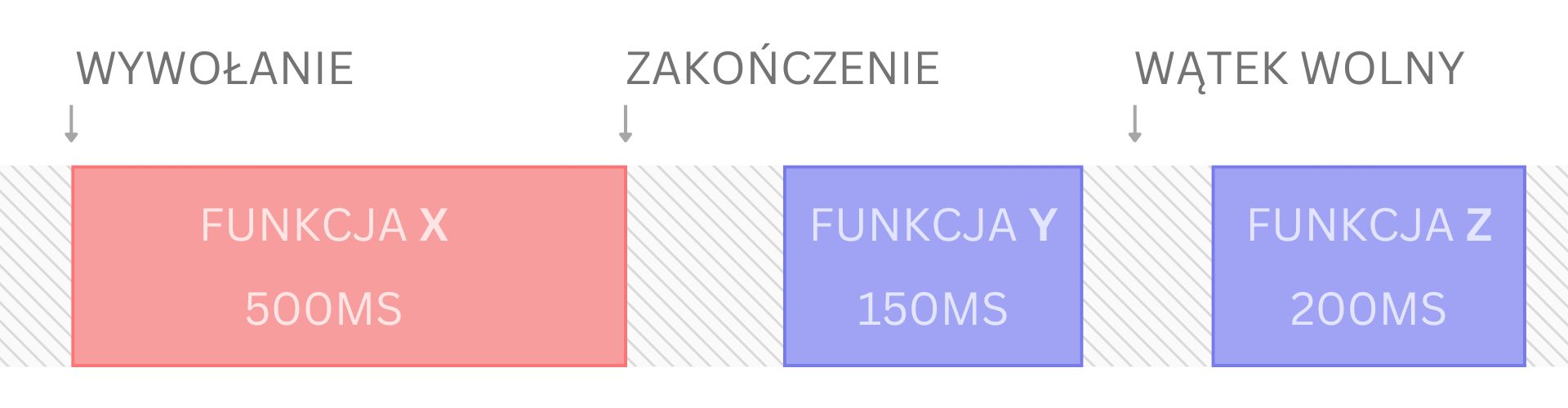
Jeżeli zastanawiasz się, dlaczego po prostu nie skorzystamy z asynchroniczności, to jest to zdecydowanie słuszne spostrzeżenie. W tym przykładzie, funkcja wykonuje zapytanie, a następnie czeka na odpowiedź od serwera, w między czasie nie robiąc nic i po prostu blokując główny wątek, a tym samym całą stronę internetową. Gdybyśmy zastosowali kod asynchroniczny, to problem zostałbym rozwiązany
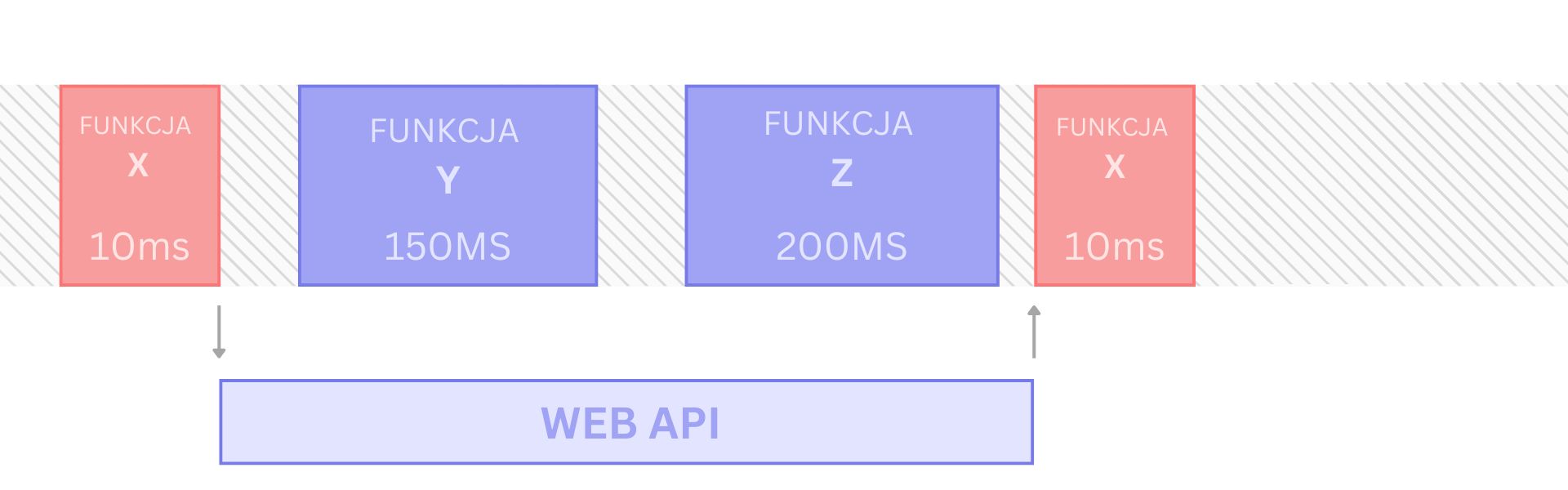
Co jednak zrobić, jeżeli nasza funkcja w ogóle nie wykonuje zapytania, a jedynie skomplikowane obliczenia, które trwają również 500ms? W takim przypadku nie możemy zastosować kodu asynchronicznego, ponieważ wszystkie nasze obliczenia są synchroniczne. Rozwiązaniem tego problemu jest zastosowanie Web Workera i oddelegowanie wszystkich obliczeń do osobnego wątku.
W celu kompletności wspomnę tylko, że nie jest to jedyne wyjście. Istnieją inne techniki, które także mogą okazać się skuteczne w tym przypadku. Przykładem może być zastosowanie Yield to Main Thread (twórcy React korzystają z tej techniki w celu zachowania responsywności aplikacji podczas wykonywania wewnętrznego kodu biblioteki), jednak szczegółowe jej omówienie wykracza poza zakres tego artykułu.
Jak w takim razie będzie wyglądać ten sam schemat jeśli zastosujemy workera?
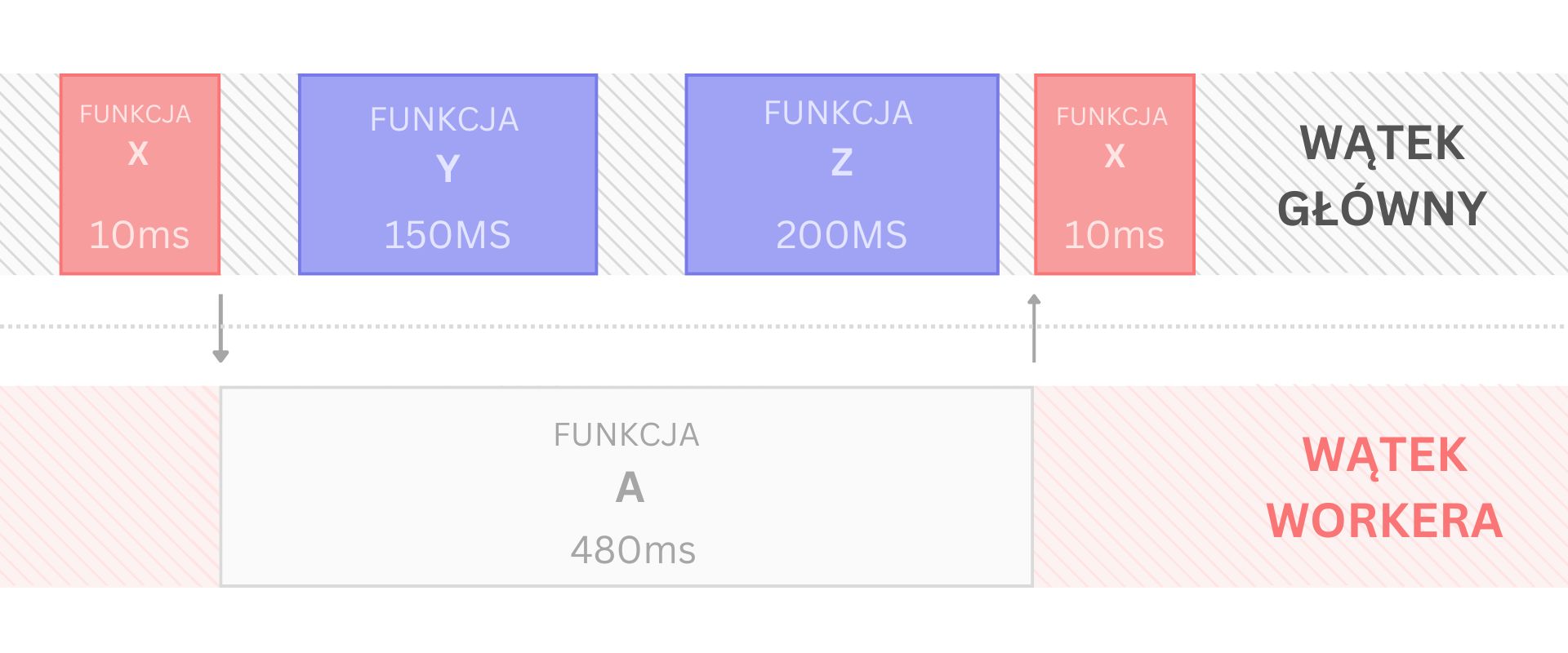
Podobnie, jak w przypadku zadania asynchronicznego. Zamiast wykonywać obliczenia w wątku głównym, prosimy o to wątek workera, a za pomocą metody postMessage przesyłamy wszelkie potrzebne informacje. Gdy tylko obliczenia się zakończą, worker powiadamia wątek główny i przesyła oczekiwany wynik.
Jak w takim razie będzie wyglądać to w kodzie?
Przede wszystkim kod workera powinien znaleźć się w osobnym pliku JavaScript. Takie podejście ułatwi jego późniejsze wykorzystanie w aplikacji. Zacznijmy od napisania prostego skryptu, którego jedynym zadaniem będzie odebraniem dwóch liczb z wątku głównego (aplikacji), zsumowanie ich, a następnie odesłanie wyniku. Nie jest to wyjątkowo obciążające dla procesora zadanie, ale w zupełności wystarcza do zrozumienia podstaw:
Skrypt gotowy. Czas połączyć go z aplikacją. Dla zachowania przejrzystości utworzymy jeden plik JavaScript, który docelowo powinien zostać połączony z HTMLem. Nic jednak nie stoi na przeszkodzie, żeby zastosować poniższy kod w aplikacjach opartych na popularnych frameworkach, jednak w takim przypadku upewnij się, że kod odpowiedzialny za tworzenie workera wywoływany jest tylko raz. Bardzo łatwo jest popełnić błąd i umieścić go w funkcji (np. komponencie Reacta), która jest wielokrotnie wywoływana w cyklu życia aplikacji.
Komunikacja pomiędzy workerem, a wątkiem głównym odbywa się za pomocą metody postMessage oraz nasłuchiwacza na zdarzenie message. Warto w tym miejscu zaznaczyć, że za pomocą metody postMessage można przesyłać jedynie dane, które mogą być serializowane za pomocą algorytmu Structured Clone. Nie można zatem przesyłać między innymi funkcji, węzłów DOM i kilku innych rzeczy.
To, co do tej pory omówiliśmy, to oczywiście jedynie wierzchołek góry lodowej, a workery mogą być znacznie bardziej przydatne, niż w przykładzie powyżej. Przykładowo autor tego artykułu pokazuje w jaki sposób można wykorzystać wątek poboczny do uruchomienia biblioteki Redux i połączenia jej z aplikacją zbudowaną z użyciem Reacta.
Przenoszenie kodu niezwiązanego bezpośrednio z UI to również znacznie szerszy temat, który zazwyczaj występuje pod nazwą OMT, czyli Off the Main Thread. Jeżeli chciał(a)byś się w niego zagłębić, to świetny punkt startowy znajdziesz tutaj.
Service Worker
To prawdopodobnie najbardziej popularny z dostępnych workerów. Wiele aplikacji internetowych wykorzystuje go, żeby zagwarantować poprawne działanie, nawet w przypadku braku połączenia z internetem. Można o nim myśleć, jak o proxy pomiędzy aplikacją, a światem zewnętrznym (internetem) z pomocą którego możemy zaimplementować takie funkcjonalności jak powiadomienia push, cache, czy przechwytywanie zapytań HTTP. Najczęściej stosowany jest w aplikacjach PWA (ang. Progressive Web Application).
Warto w tym miejscu zaznaczyć, że rejestracja Service Workera odbywa się nieco inaczej. W tym przypadku skrypt jest instalowany na urządzeniu użytkownika. Oznacza to, że Service Worker może pozostać aktywny nawet po zamknięciu strony internetowej. Dzięki temu, nawet gdy użytkownik nie korzysta z naszej aplikacji, możemy wysyłać powiadomienia push lub synchronizować dane w tle (np. pobierać najnowsze artykuły, by móc je później wyświetlić w przypadku braku połączenia z internetem).
Komunikacja również wygląda nieco inaczej niż poprzednio. Mimo, że nadal możemy wykorzystywać metodę postMessage, to w praktyce rzadko się to robi. Zamiast tego, zazwyczaj skupiamy się na obsłudze zapytań HTTP i cache’owaniu zasobów (np. obrazków, skryptów lub arkuszy styli).
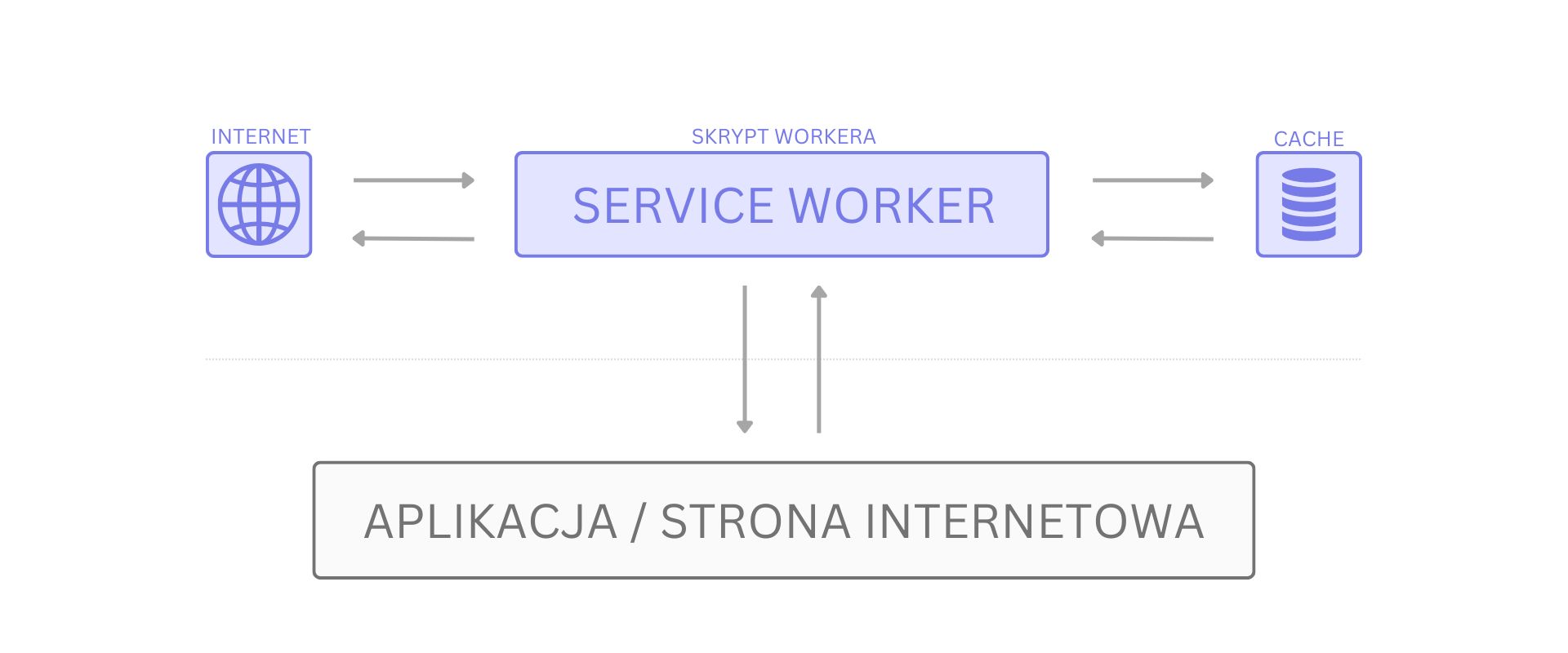
Kod również znacząco odbiega od tego, co widzieliśmy wcześniej:
Ta prosta implementacja spełnia tylko jedno zadanie - przechwytuje zapytania HTTP i sprawdza, czy zostały one już wcześniej zapisane w pamięci. Jeżeli tak, to zwracamy zapisaną wcześniej wersję. W innym przypadku po prostu wykonujemy zapytanie.
Podsumowując: Service Worker zachowuje się jak osobna aplikacja działająca niezależnie od strony internetowej. Potrafi pozostawać aktywny, nawet wtedy, gdy użytkownik nie korzysta obecnie z naszej witryny. Pełni rolę proxy, chroniącego dostępu do strony, potrafi przechwytywać zapytania HTTP, wysyłać powiadomienia push, a także zapisywać w pamięci pobrane wcześniej zasoby, co umożliwia ich wyświetlanie nawet w trybie offline.
Z kolei Web Worker pozostaje aktywny tylko wtedy, gdy użytkownik korzysta z naszej aplikacji (i krótko po jej zamknięciu). Jego głównym celem jest wykonywanie czasochłonnych obliczeń i odciążenia wątku głównego (UI).
Co ważne, wykorzystanie jednego z nich nie wyklucza użycia drugiego. Możemy jednocześnie wykorzystywać zarówno Service Workera, jak i Web Workera (lub wiele Web Workerów).
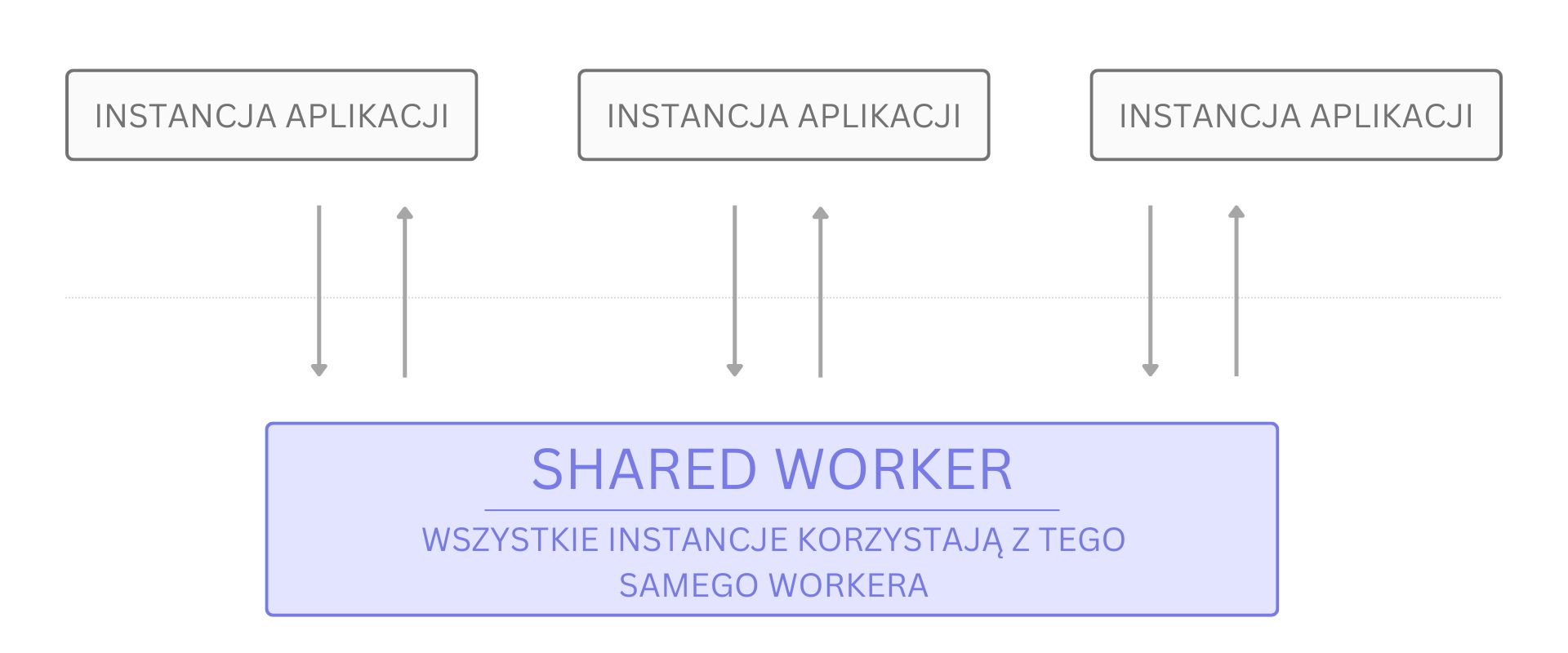
Prawdopodobnie najrzadziej wykorzystywany z workerów. Jak sama nazwa wskazuje, jest on dzielony pomiędzy wieloma instancjami tej samej strony. Najczęściej wykorzystuje się go do synchronizacji stanu lub innych danych, które powinny być spójne w każdej otwartej karcie lub oknie. Spotkałem się również z wykorzystaniem tego typu workera do wykonywania cyklicznych zapytań do serwera, żeby uniknąć ich powielania w przypadku wielokrotnego otwarcia aplikacji. Muszę się jednak przyznać, że do tej pory sam nie wykorzystałem go ani razu w komercyjnym projekcie.
Jak w takim razie wygląda komunikacja? Niemal identycznie jak w pierwszym przypadku. Jedyna zauważalna różnica, to większa liczba klientów korzystających jednocześnie z tego samego wątku workera.
Także w przypadku kodu nie dopatrzymy się wielkich różnic. Oczywiście zależy to od indywidualnych potrzeb projektu i może się okazać, że w Twoim projekcie wykorzystasz go w zupełnie innych celach, a co za tym idzie, także kod będzie wyglądać zupełnie inaczej.
Największa zmiana polega na wykorzystaniu właściwości ports z obiektu event. Przechowuje ona obiekty, które odpowiadają połączonym z workerem instancjom aplikacji. Zamiast dodawać nasłuchiwacz zdarzeń do obiektu globalnego, dodajemy go do pierwszego portu (czyli do pierwszej połączonej aplikacji).
Podobnie sytuacja wygląda w przypadku wysyłania odpowiedzi. Zamiast wykorzystywać metodę postMessage z obiektu globalnego, używamy zmiennej port, która przechowuje obiekt odpowiedzialny za komunikację z daną instancją.
Podsumowując: Shared Worker jest wykorzystywany niezwykle rzadko, ale może okazać się niezastąpiony, gdy kilka jednocześnie otwartych instancji naszej aplikacji powinno współdzielić stan lub synchronizować między sobą inną logikę. Zanim jednak zdecydujesz się na zastosowanie Shared Workera, sprawdź, czy inne rozwiązania (np. localStorage, który również może posłużyć do synchronizacji stanu pomiędzy wieloma kartami) nie są w Twoim przypadku lepszym wyborem, choćby z uwagi na mniejszy stopień skomplikowania lub łatwiejszą implementację.
Ograniczenia i Kompromisy
W świecie programowania nie ma niestety nic za darmo. Jeżeli jakieś rozwiązanie ma plusy, to musi mieć również minusy. Uniwersalne, działające dla wszystkich przypadków wzorce i algorytmy po prostu nie istnieją. Tak samo jest w przypadku workerów.
Co w takim razie musimy poświęcić, żeby uzyskać namiastkę wielowątkowości we frontendzie?
Wydajność - komunikacja pomiędzy workerem, a wątkiem głównym niestety nie jest darmowa. Metoda
postMessageserializuje dane do postaci w której mogą być przesłane do workera. Następnie czynność ta jest odwracana (dane są deserializowane) po stronie workera. Im więcej danych przesyłamy i im bardziej skomplikowana jest ich struktura, tym dłużej zajmie ten proces. Więcej na temat wydajności metodypostMessagemożesz znaleźć w tym artykule.
Prostota kodu - wykorzystanie dowolnego rodzaju workera zawsze wiąże się z dodatkową warstwą abstrakcji, a sam kod zaczyna być nieco bardziej skomplikowany. Im więcej danych przesyłamy i odbieramy, tym bardziej zawiły się staje.
Programiści często starają się rozwiązać ten problem, tworząc własny zestaw klas, funkcji lub obiektów, za pomocą których komunikują się z workerem. Takie rozwiązanie niesie za sobą ryzyko utworzenia interfejsu, który jest nieintuicyjny lub po prostu trudny do zrozumienia. Należy pamiętać, że ukrywanie natywnych dla przeglądarek funkcjonalności nakłada niejako obowiązek nauczenia się nowego API przez każdego członka zespołu. Problem ten nie występuje w przypadku API dostarczonych przez przeglądarki lub sam język programowania ponieważ są one dobrze znane wśród programistów danego języka.
Dodatkowo musimy pamiętać, że nie wszystkie dane mogą zostać przesłane. To z kolei może prowadzić do błędów, których debugowanie będzie trudniejsze niż w przypadku standardowego kodu.
Dostęp do niektórych API - kod wykonywany w wątku workera nie może korzystać ze wszystkich API dostarczanych przez przeglądarki. Przede wszystkim nie mamy tu dostępu dom DOM, jednak na tym lista się nie kończy. Przed wykorzystaniem danej funkcjonalności, najlepiej jest sprawdzić, czy jest ona dostępna poza wątkiem głównym. Warto również wziąć pod uwagę, że nie mamy tu dostępu do obiektu window. Zamiast tego, obiektem globalnym jest w tym przypadku
self.
Warto wspomnieć, że społeczność stworzyła wiele bibliotek, które mogą okazać się przydatne podczas pracy z workerem. Jedną z najbardziej znanych jest Comlink, który w znacznym stopniu ułatwia komunikację pomiędzy wątkami i zapewnia dobrze udokumentowane API. Nie rozwiązuje on co prawda problemu związanego z wydajnością i koniecznością serializacji, jednak dopóki nie przesyłamy wielokrotnie zagnieżdżonych obiektów, których rozmiar przekracza około 100 kilobajtów, to nie powinna ona być problemem.
Zwróć uwagę, że większość wymienionych powyżej ograniczeń nie dotyczy Service Workera. Zasada jego działania jest nieco inna niż w przypadku dwóch pozostałych typów (choć nadal występuje tu komunikacja z wątkiem głównym). Różnią się także przypadki w jakich chcemy go wykorzystać. Co prawda istnieje kilka alternatywnych rozwiązań (Cache API, IndexedDB), jednak żadne z nich nie zastępuje w pełni możliwości, jakie daje nam Service Worker. W praktyce oznacza to, że niemal wszystkie aplikacje zapewniające działanie w trybie offline wykorzystują właśnie tę technologię.
Podsumowanie
Web Workery są od dawna wspierane przez wszystkie główne przeglądarki. Mimo to nie doczekały się szerokiego zastosowania w świecie frontendu. Wykorzystuje się je sporadycznie i jedynie Service Worker przebił się do czegoś, co można określić jako mainstream.
Głównym powodem takiego stanu rzeczy jest prawdopodobnie fakt, że większość aplikacji i stron internetowych można określić jako “data intensive”, a więc takie, które przesyłają i odbierają znaczne ilości danych. Z kolei wykorzystanie Web Workera da największe korzyści w aplikacjach typu “computation intensive”, czyli takich, które wykonują wiele skomplikowanych i czasochłonnych obliczeń.
Nie oznacza to jednak, że nie powinnaś lub nie powinieneś wykorzystać go w swojej aplikacji. Wręcz przeciwnie. Jeżeli tylko widzisz pole do poprawy wydajności, to warto sprawdzić, czy jeden z workerów nie okaże się w Twoim przypadku przydatny. Weź jednak pod uwagę minusy, które niesie za sobą wykorzystanie go.
Jak zawsze w przypadku programowania, tak i tu, warto jest eksperymentować i kiedy to tylko możliwe, sprawdzać nowe rozwiązania problemów. Być może okażą się lepsze, niż dotychczasowe podejście, do którego jesteś przyzwyczajony/a.




